등록 : 2019.03.29 15:50
수정 : 2019.04.05 16:14
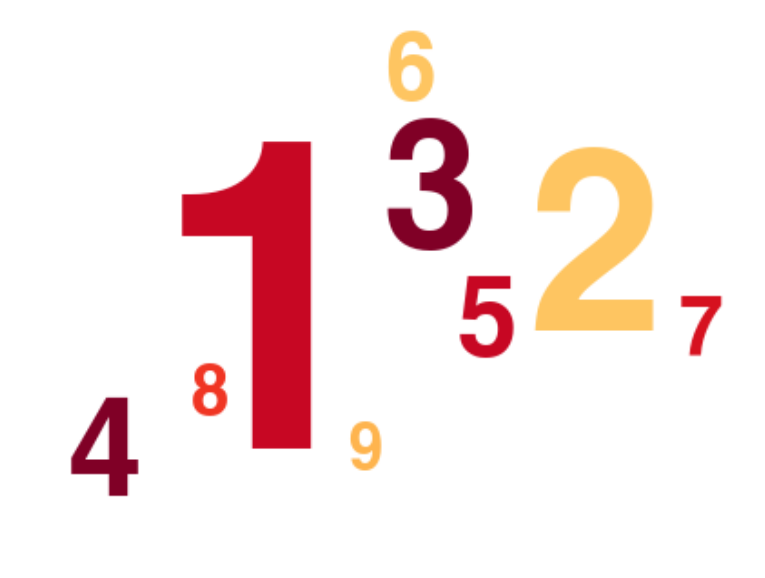 |
|
벤포드 법칙의 각 숫자 등장 비율에 따라 크기를 맞춰 그린 워드클라우드. 권오성
|
무수한 데이터에 등장하는 첫 번째 숫자 비율은
신기하게도 1 > 2 > 3 > 4 >…의 순이 많아
물리학자 벤포드가 공식화한 ‘벤포드의 법칙’
소셜네트워크와 금융 데이터 등에서
‘수상한 숫자’를 잡아내는 데 유용한 경험칙
|
|
|
벤포드 법칙의 각 숫자 등장 비율에 따라 크기를 맞춰 그린 워드클라우드. 권오성
|
 |
|
칼럼, 권오성, 권오성의 세상을 바꾼 데이터
|
세상 수많은 데이터의 숫자들 가운데 시작 숫자는 무엇이 많을까? 시작 숫자란 긴 숫자의 첫 번째 숫자를 말한다. 예컨대 365의 시작 숫자는 ’3’이다. 무작위 데이터 가운데 무슨 숫자가 처음에 많이 등장할지는 언뜻 우스운 질문처럼 보인다. 1부터 9까지 숫자가 무작위로 나오는 것이 당연해 보이니 말이다. 하지만 ‘벤포드의 법칙’은 그렇지 않다고 말한다. ‘1’이 가장 높은 비율로 나타나고, 그다음이 ‘2’, 다음이 ‘3’ 등으로 비율이 순서대로 낮아진다는 것이 벤포드 법칙이다.
이 법칙은 1938년 미국의 물리학자 프랭크 벤포드가 발표하면서 그의 이름을 따 붙었다. 하지만 그에 앞서 미국 천문학자 사이먼 뉴컴이 1881년 먼저 이런 경향을 언급한 바 있다. 벤포드는 20개의 서로 다른 데이터셋들을 비교한 결과, 모두 시작 숫자의 비율이 희한하게 비슷하다는 점을 발견했다. 대상에는 335개 강의 표면적, 104개의 물리학 상수, 1800개의 분자 무게, 5000개의 수학책에 나오는 숫자, 308개의 잡지 <리더스 다이제스트>에 나오는 숫자 등이 포함됐다. 조사 결과 놀랍게도 이 데이터에 등장하는 첫 번째 숫자의 비율은 모두 다음과 비슷하게 나타났다.
 |
|
벤포드의 법칙에 따라 각 숫자의 등장 비율을 나타낸 표. 위키피디아 갈무리
|
벤포드는 이 비율을 공식으로 표현했다. 해당 공식은 다음과 같다.
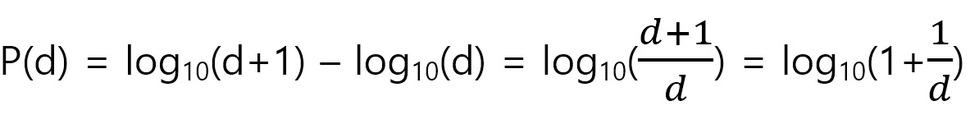 |
|
벤포드 법칙의 공식.
|
공식에서 P(d)란 d라는 숫자가 데이터에서 첫 번째 숫자로 나타날 확률을 의미한다. 예를 들어 ‘1’이 나타날 확률을 공식에 대입해 보면 log(1+1/1), 즉 log(2)가 된다. log(2)의 값은 약 0.301이다. ‘2’가 나타날 확률은 log(1.5)이며 이는 약 0.176이다. 이런 식으로 ‘9’까지 위의 표와 같은 비율이 나오는 것이다.
왜 이런 현상이 나타날까? 일부 설명을 시도한 예들은 있지만, 기본적으로 벤포드 법칙은 엄밀한 법칙이 아니기 때문에 명확한 설명은 있을 수 없다. 즉, 이 법칙은 수학적으로 명확하게 증명이 된 바는 없다는 말이다. 그저 이런 현상이 제법 잘 관찰된다는, 경험칙일 뿐이다. 예를 들어, 성인의 키를 미터법으로 나타낸 데이터를 떠올려 보자. 당연히 어떤 인구를 대상으로 하더라도 ‘1’이 30%를 넘어 압도적으로 높게 나타나리라는 것은 누구나 알 수 있다. 하지만 만약 키를 미국에서 쓰는 피트(1피트는 30.48㎝) 단위로 나타낸다면 ‘5’나 ‘6’이 매우 높게 나타날 것이다. 즉 어떤 경우냐에 따라 벤포드의 법칙은 애초에 전혀 맞지 않을 수도 있는 셈이다.
하지만 벤포드가 이를 발표한 뒤 여러 사람이 꽤 많은 데이터가 희한하게도 이 법칙에 제법 잘 들어맞음을 발견했다. 가장 높은 건물들의 높이, 주소의 번지, 전기세, 주식 가격, 집값, 인구, 사망률 등에서 이 비율이 관찰됐다.
이런 특징은 데이터의 진위 판별에 유용하게 쓰일 수 있다. 실제 이를 보인 연구가 있었다. <엠아이티 테크놀로지 리뷰>(MIT Technology Review)에 의하면, 미국 메릴랜드 대학교의 제니퍼 골벡(Jennifer Golbeck) 교수(컴퓨터 과학)는 2015년 소셜네트워크의 데이터와 벤포드 법칙의 관계에 대한 연구 결과를 발표했다. 골벡 교수는 페이스북, 트위터 등의 계정들에서 친구의 친구 숫자(한 계정의 친구들이 가지고 있는 친구 또는 팔로워의 숫자)와 벤포드 법칙과 관계를 살펴봤다. 그 결과 놀랍게도 대부분의 숫자가 법칙과 잘 들어맞는 것을 발견한 것이다. 예를 들어 조사한 트위터 계정 2만1천개의 경우 대부분이 0.9 이상의 상관계수(최대 1)로 벤포드 법칙의 비율과 유사하게 나타났다. 단지 170개 계정만이 0.5 미만의 상관계수를 보였다. 그런데 이들 계정을 자세히 조사해 보니 이유가 드러났다. 대부분이 진짜 사람이 운영하지 않는 이른바 ‘트윗봇’이라는 허구의 계정이었던 것이다.
벤포드 법칙의 이런 특징은 대량의 숫자가 발생하는 금융 데이터 등에서 특히 유용하게 쓰일 수 있다. 비록 벤포드 법칙을 따르지 않는다고 그 숫자가 바로 문제가 있다고 결론지을 수는 없다. 하지만 이런 숫자들은 우선 의심해볼 만하다는 것이다. 즉, 1부터 9까지 숫자가 비슷한 비율로 무작위로 등장하는 숫자는 누군가 허위로 만들어낸 ‘가짜 숫자’일 수 있다는 뜻이다.
권오성 기자 sage5th@hani.co.kr
광고

){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
기사공유하기