 |
|
토픽 모델링 시각화. 권오성
|
[권오성의 세상을 바꾼 데이터]
텍스트 데이터 자연어 처리 ②
한글의 토픽모델링 실험기
29년치 기사로 기계학습 해봤더니
|
|
|
토픽 모델링 시각화. 권오성
|
지난 글[링크]에서 ‘물고기(fish) + 음악(music) = 베이스(bass·물고기 배스란 뜻도 있다)’라는 신박한 해석을 내놓는 워드투벡터(Word2Vec)의 사례를 소개해 드렸다. 워드투벡터는 단어를 벡터로 치환하는 자연어처리 기술 가운데 하나다. 예에서 드러나듯 사례는 영어가 대상 언어였다.
이번에는 한글을 대상으로 ‘토픽 모델링’이라는 자연어 처리 기술을 직접 적용해 본 사례를 소개해 드릴까 한다. 지난 글을 보지 않으신 분을 위해 자연어 처리에 대해 살짝 설명 드리자면, 여기서 ‘자연어’(natural language)란 사람의 말을 뜻한다. 즉 사람의 말을 처리하는 기술이 자연어 처리다. 왜 사람의 말을 ‘처리’해야 할까? 0과 1의 수학으로 구성된 기계에게 사람의 말은 도무지 이해할 수 없는 수수께끼의 데이터인 탓이다. 이를 기계가 이해할 수 있는 방식의 데이터(벡터나 숫자)로 변환해 기계가 자신 있는 이런저런 일(빠른 연산 등)을 시켜보고, 유용한 결과를 다시 인간의 말로 변환해 취하는 것이 자연어 처리 기술의 쓰임이다.
토픽 모델링이란 어떤 기술인가. 이 기술은 어떤 문서가 ‘토픽’이라는 추상적인 무엇으로 구성되어 있다고 가정하고 이 ‘토픽’들을 찾아내는 기술이다. 예를 들어 ‘개’에 대한 글이라면 분명 글 안에 “멍멍“이나 “강아지”와 같은 단어가 “야옹”이나 “캣맘” 같은 단어보다 훨씬 많이 들어 있을 것이다. 기계는 이렇게 자주 같이 등장하는 단어들을 묶어서 하나의 토픽을 이룬다고 가정한다. 여러 문서들을 대상으로 한 문서에 자주 같이 등장하는 단어들을 통계적으로 추출해 내는 것이 토픽 모델링 기법이다.
우리가 직접 읽어도 되는 숫자의 문서라면 굳이 토픽 모델링을 쓸 필요가 없을 것이다. 2주일 치 일기 정도의 문서들이라면, 그냥 읽어만 봐도 ‘음 이 녀석이 요즘 게임에 빠져있군’하고 바로 알 수 있다. 토픽 모델링은 인간이 감당하기 어려운 숫자의 문서(수십, 수백, 수천 만개의 문서)에서 무슨 이야기들이 오가는지 알아보는 데 유용하다. 토픽의 숫자는 분석자가 원하는 데로 5개니, 100개니 정할 수 있다. 하지만 문서가 많으면 많을 수록 이런저런 토픽들이 많이 들어있을 테니 그에 맞춰 정해주는 것이 요령이다. 만약 방대한 양의 텍스트에 토픽 수를 적게 정해주면 ‘개’와 ‘고양이’ 같이 구분되어야 할 토픽도 기계는 하나로 뭉뚱그려 버릴 것이다. 반대로 텍스트에 비해 토픽 수를 너무 많이 정해주면 필요 이상으로 자세하게 나누어져서 혼란스러울 것이다.
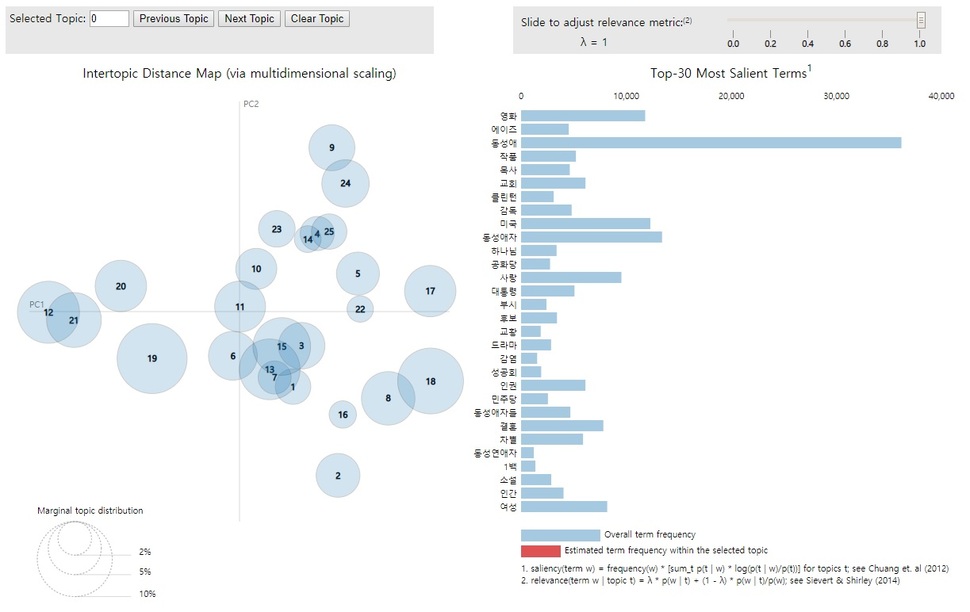
각설하고, 실제 적용해 본 사례를 보자. 대상 텍스트는 1990년부터 2018년까지 주요 일간지에 ‘동성애’라는 낱말이 들어간 기사 1만2873개이다. 굳이 ‘동성애’를 삼은 이유는 지난해 한국언론진흥재단에서 주최한 뉴스 빅데이터 활용 공모전에 응모한 주제 가운데 하나였기 때문이다(덕분에 재단으로부터 텍스트를 쉽게 구할 수 있었다). 지난해 ‘미투 운동’ 등 소수자 운동이 활발히 전개되는 분위기에서 주요 소수자 관련 기사가 과거부터 지금까지 어떤 토픽을 다뤘는지 보려고 몇 개 소수자 단어를 뽑았는데, ‘동성애’는 그 가운데 텍스트 양이 가장 적은 주제어였다. 1만2873개는 주요 일간지 6개에서 뽑은 숫자인데, <한겨레>, <경향>, <국민>, <세계>, <서울>, <한국> 등이었다. 이들 신문만 언론재단 ‘빅카인즈’ 데이터베이스에 1990년부터 2018년까지 기사가 누락 없이 완결적으로 수록돼 있었다.
여기서 토픽을 뽑아내려면 우선 전처리를 해줘야 한다. 아시다시피 기사는 우리가 이해할 수 있는 글로 구성되어 있는데 이를 단어 단위로 해체해 주는 게 전처리의 요체다. 우리나라 말에서 특히 어려운 것은 용언이다. 워낙 어미 변화가 무쌍하기 때문에 동사나 형용사를 의미에 맞게 적절히 해체하기 매우 어렵다. 그래서 일단 명사만 대상으로 삼았다. 마침 고맙게도 빅카인즈 서비스는 기사 별로 명사만 추출한 데이터를 ‘키워드’라는 항목으로 따로 제공하고 있다.
이렇게 자연어의 문법과 단어 순서를 무시하고 텍스트를 그냥 단어의 집합으로 보는 방식을 ‘단어 자루’(Bag-of-words) 모델이라고 하는데(문서를 그냥 단어가 담긴 자루로 보는 것이다), 토픽 모델링도 단어 자루 분석법 그룹의 일원인 셈이다. 빅카인즈의 ‘키워드’ 항목 제공은 단어 자루 방식 분석에 매우 유용하다 하겠다.
토픽의 숫자는 25개로 설정했다. 이유는 여러 크기의 다른 텍스트들을 분석해보고, 적절한 토픽 숫자를 가늠해주는 알고리즘 등을 돌려본 뒤 결정한 개수다. 물론 여기에 정답은 없다. 가장 적절한 토픽 숫자는 많은 경험과 다양한 실험에서 나온다고 한다. 실제 구현 도구는 파이썬(Python)이라는 프로그래밍 언어를 이용하였으며, 파이썬의 유명한 자연어 처리 라이브러리 가운데 하나인 젠심(gensim)을 활용하였다.
파이썬 토픽 모델링의 결과를 보는 가장 좋은 방법은 시각화 패키지(pyLDAvis)를 활용하는 것이다. 그 결과는 다음과 같다. 이 시각화 패키지는 인터랙티브한 웹 페이지를 생산해 내지만, 본 기사 페이지에선 이를 표시하는 게 이런저런 이유로 어렵다. 그래서 갈무리한 그림 파일로 설명함을 양해해 주시기 바란다.
 |
|
토픽 모델링 시각화. 권오성
|
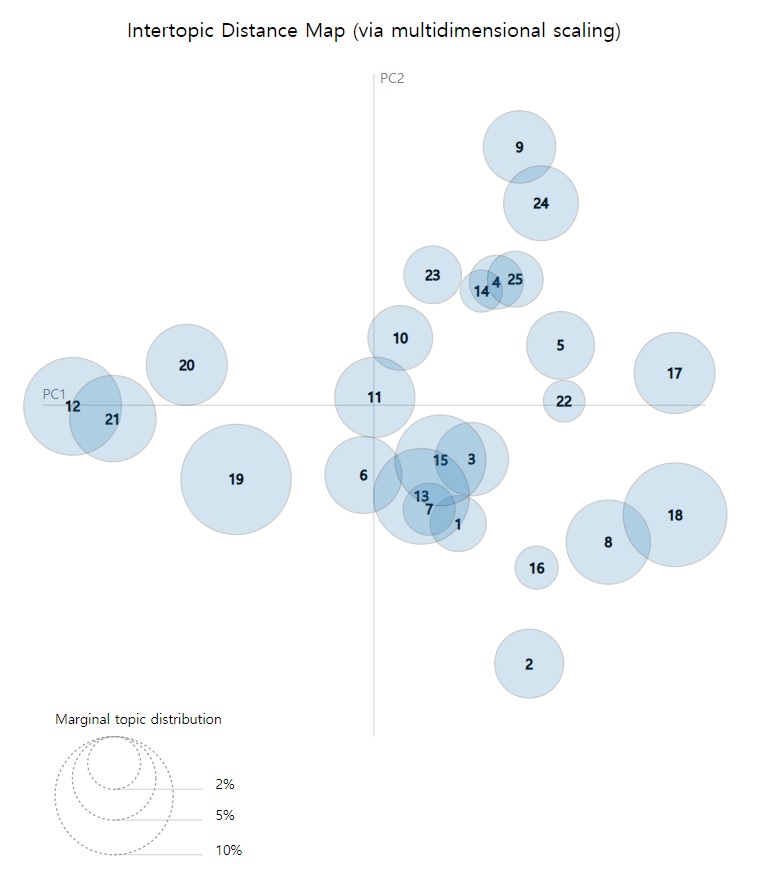
여기서 각 동그라미는 토픽을 말한다. 수를 25개로 설정하였으므로 1번부터 25번까지 토픽이 있다. 동그라미의 크기는 그 토픽이 전체 텍스트에 얼마나 많이 나타나는지 뜻한다. 클수록 토픽의 비중이 크다는 이야기다. 동그라미 사이 거리는 해당 토픽이 얼마나 가까운지를 뜻한다. 즉 거리가 가까울수록 두 토픽이 한 문서 안에 자주 함께 등장한다는 뜻이다.
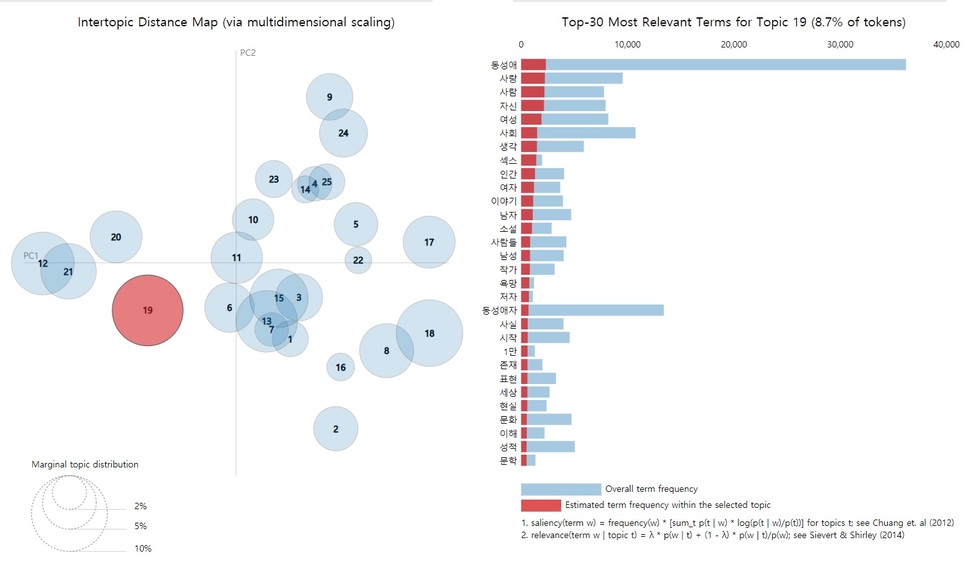
이 토픽 모델링에서 가장 큰 토픽은 19번임을 알 수 있다. 19번을 클릭하면 다음과 같은 결과가 나온다.
 |
|
토픽 모델링 시각화. 권오성
|
오른쪽 상위 30개 단어(Top-30 Most Relevant Terms)가 19번 토픽에 맞춰 바뀐 것을 볼 수 있다. 1위는 ‘동성애’이다. 앞서 토픽 모델링이 자주 함께 등장하는 단어로부터 토픽을 도출한다고 설명한 바 있다. 그런데 한 단어가 꼭 한 토픽에만 배정되어야 하는 것은 아니다. 19번 토픽의 1위 단어로 꼽힌 ‘동성애’ 같은 단어는 모든 기사에 꼭 들어가 있는 단어이므로 모든 단어와 다 함께 등장했을 것이다. 따라서 19번뿐 아니라 모든 토픽에 등장하는 단어일 것이다. 그만큼 큰 의미는 없다. 보다 중요한 단어는 이 토픽에 특별한 다음 단어들이다. ‘사랑’, ‘사람’, ‘자신’, ‘여성’, ‘사회’, ‘생각’, ‘섹스’ 등이다. 이것은 무슨 토픽일까? 아마도 동성 간 사랑, 그 가운데 여성에 대한 이야기일 가능성이 높아 보인다.
이런 것이 토픽 모델링이 인간의 텍스트로부터 추출해서 인간에게 돌려줄 수 있는 통찰이다. 지난 30년 동안 동성애에 대한 수많은 이야기가 있었을 것이다. 방송인 홍석천씨가 동성애임이 알려지자 퇴출되다시피 하던 시기가 이 사이였고, 동성 간 결혼이 큰 이슈로 떠오르기도 하였고, 기독교 쪽의 적극적인 ‘반대’ 주장이 나온 것도 이 시기 안에 있었기 때문이다. 그럼에도 지난 29년 동안 신문에서 다룬 동성애 이야기 가운데 가장 비중이 높은 것이 ‘여성 간의 사랑’에 대한 이야기일 가능성이 높다는 점은 의외다.
여기서 가능성이라 하는 이유는 실제 텍스트가 어떠한지 추가로 살펴보아야 하기 때문이다. 19번 토픽의 단어들은 의미의 넓이가 상당히 넓은 추상적 단어들이다(‘홍석천’과 같은 단어에 비교한다면). 이들만으로는 기사의 내용을 구체적인 수준까지 짐작하긴 어렵다. 또 토픽 모델링은 ‘단어 자루’식의 분석이기 때문에 단어가 엮이는 방식에 따라 맥락이 달라지는 데에는 취약하다. 비록 중요 단어는 이렇게 나타나지만 실제 텍스트의 맥락은 다를 수도 있기 때문이다(예를 들어 ‘사랑 하는 여성과 꼭 섹스를 해야 한다고 생각하는 사람이 많은 사회는 문제가 많다’라는 식의 기사들이 잔뜩 있었더라도 저런 결과가 나타났을 것이다).
아무튼 이렇게 나머지 톱3 토픽의 단어를 보면 다음과 같다.
톱2(토픽 11) = [영화, 작품, 감독, 작가, 소설, 관객, 영화제, 소재, …]
톱3(토픽 14) = [여성, 사회, 성적, 청소년, 남성, 인정, 경험, 행위, …]
토픽 11은 그 특징이 보다 또렷하다. ‘영화’에 대한 내용임을 한눈에 알 수 있다. 동성애 관련해서 영화에 대한 기사가 얼마나 큰 비중을 차지하는지 알 수 있다. 영화가 동성애에 대한 인식을 바꾸는 데 큰 공헌을 하지 않았을까 추정해 볼 수 있다. 토픽14는 상대적으로 모호한 편이다. 19번 토픽과도 좀 비슷해 보인다. ‘청소년’, ‘남성’, ‘인정’ 등의 단어가 좀 다른 맥락을 보인다.
몇 가지 특징이 나타나긴 하지만 이렇게 전체 텍스트에 대한 토픽만으로는 아직 감을 잡기 어렵다. 1990년부터 2018년 사이 시기별로 무슨 토픽이 주요하게 나타나는지 볼 수 있을까? 가능하다. 그 내용을 다음 글에서 다룬다.
권오성 기자 sage5th@hani.co.kr
본 보도는 한국언론진흥재단 빅카인즈의 지원을 받았습니다.
광고

){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}
);)

);)
);)

기사공유하기