등록 : 2019.08.09 16:21
수정 : 2019.08.09 18:48
 |
|
삼성 연구진이 개발한 ‘말하는 머리’(Talking Heads) 인공지능이 내놓은 사례. 이 인공지능은 퓨-샷 러닝(few-shot learning)이라는 기술을 이용해 한 장의 원본사진(왼쪽 첫번째 줄)만으로 여러 가상의 사진(오른쪽 사진들)을 만들어 낼 수 있다. 아카이브 논문에서 갈무리. https://arxiv.org/abs/1905.08233
|
[권오성의 세상을 바꾼 데이터]
하이브리드 인공지능, NSCL
퓨-샷 러닝, 삼성의 ‘말하는 머리’
인공지능이 만든 가상 학습용 데이터 등
데이터 축적 없이 가능한 AI 기술 소개
|
|
|
삼성 연구진이 개발한 ‘말하는 머리’(Talking Heads) 인공지능이 내놓은 사례. 이 인공지능은 퓨-샷 러닝(few-shot learning)이라는 기술을 이용해 한 장의 원본사진(왼쪽 첫번째 줄)만으로 여러 가상의 사진(오른쪽 사진들)을 만들어 낼 수 있다. 아카이브 논문에서 갈무리. https://arxiv.org/abs/1905.08233
|
인공지능은 두말할 필요 없는 중요한 기술이다. 하지만 활용이 쉬운 기술은 아니다. 데이터 때문이다. 예컨대 가까운 미래에 어떤 식당에서 서빙과 설거지에 인공지능 로봇 종업원을 쓰고자 한다고 해보자. 식당 주인은 로봇을 데려다 놓고도 한참을 기다려야 할 것이다. 왜냐면 만약 지금의 기계학습 여건이라면 로봇이 그 식당 고유의 접시를 정확히 구분하는 데에만 수십, 수백만장의 각종 각도와 상황의 접시 사진이 학습에 필요할 것이기 때문이다. 놀라운 인공지능을 얻기 위해선 그만큼 ‘빅’ 데이터가 필요한데, 데이터를 많이 축적하는 건 쉬운 일이 아니다.
그런데 요즘 이런 ‘빅데이터 문제’에 대한 희소식이 들리고 있다. 해결의 실마리를 제공할 여러 가지 기술이 잇따라 등장하고 있기 때문이다. 소프트웨어 개발자이자 유명 블로거인
벤 딕슨이 <벤처비트>에 기고한 글[링크]에서 이런 기술을 종합했다.
■ 하이브리드 인공지능
매사추세츠공대(MIT)와 아이비엠(IBM)의 연구진은 지난 5월 열린 표현 학습 국제 학회(ICLR)에서
‘신경-상징 개념 학습자’(NSCL·Neuro-Symbolic Concept Learner)[링크]라는 새 인공지능을 선보였다. 지난 수십 년의 인공지능 발전 역사를 돌아보면 접근법이 크게 둘로 나뉜다. 하나는 지능의 원리를 분명한 코드로 짜야 한다는 ‘전문가 시스템’파이고, 다른 하나는 지금의 열풍을 가져온 컴퓨터가 스스로 익히도록 하는 ‘기계학습’파이다. 그런데 신경-상징 개념 학습자는 둘을 결합한 ‘하이브리드’ 인공지능이라는 게 특징이다.
이 인공지능은 우선 일부 데이터로부터 학습을 통해 대상의 특징을 뽑아낸다. 그리고 나선 이를 저장해두고 전통의 전문가 시스템 기법을 결합해 문제 해결에 활용하는 것이다. 둘의 결합을 통해 훨씬 적은 수의 데이터만으로도 비슷한 문제 해결 능력을 발휘할 수 있다는 게 연구진의 설명이다.
■ 퓨-샷 러닝(few-shot learning)
적은 데이터로도 우수한 능력을 발휘하기 위한 노력은 기존에도 있었는데 그 가운데 하나가
학습 전송(transfer learning)[링크]이다. 이는 쉽게 말해 어떤 사람이 빅데이터를 가져다 모델을 구축하고 이를 공개하면, 그 모델을 가져다가 필요에 따라 약간의 추가 데이터로 학습을 시켜서 자기 필요에 맞게 활용하는 것이다. 도입에서 예로 든 로봇 종업원의 경우 이미 만들어진 ‘공개 종업원 인공지능 버전 1’을 가져다 우리 가게 접시로 좀 추가 학습을 시켜서 써먹는 것이다. 하지만 이 경우에도 수백 개의 데이터와 많은 시행착오 공정을 거쳐야 했다.
근래에 단 몇 개의 데이터 만으로도 이런 기능을 활용할 수 있는 기술이 등장해 눈길을 끌었다. 이런 기술을 퓨-샷 러닝(few-shot learning)이라 한다. 삼성의 연구진은 지난 5월
‘말하는 머리’(Talking Heads)라는 얼굴 애니메이션 인공지능을 소개했다[링크]. ‘말하는 머리’는 얼굴 비디오에 대한 빅데이터 학습을 통해 핵심 부위와 그 특징이 무엇인지 잡아냈다. 그 뒤에는 학습에 썼던 사람의 비디오가 아니라 처음 보는 인물의 사진 몇 장만 가지고도 그 사람의 다른 표정과 각도의 사진을 마음대로 생성해 낼 수 있는 것이다. 이런 기능이 우리 로봇 종업원에게 도입된다면 접시 몇 개만 보면 바로 일을 시작할 수 있을 것이다. 물론 이런 기술은 어떤 사람이 하지도 않은 행동과 말을 한 것처럼 영상과 사진을 꾸며내는 ‘딥 페이크’ 문제를 더 심화할 위험도 있을 테다.
■ 인공지능으로 데이터를 만들어 버리자
만능으로 불리는 인공지능이라면 빅데이터 문제도 직접 해결할 수 있지 않을까? 물론, 가능하다! ‘생성적 적대 신경망’(GANs)이라는 인공지능계의 새 스타 덕분이다. 생성적 적대 신경망은 속이려는 인공지능과 속지 않으려는 인공지능 둘을 만들어 서로 싸움을 붙이고 그 사이에서 놀라운 결과를 얻어내는 기술이다. 지난달 독일 뤼베크 대학의 연구진은 이 기술을 이용해
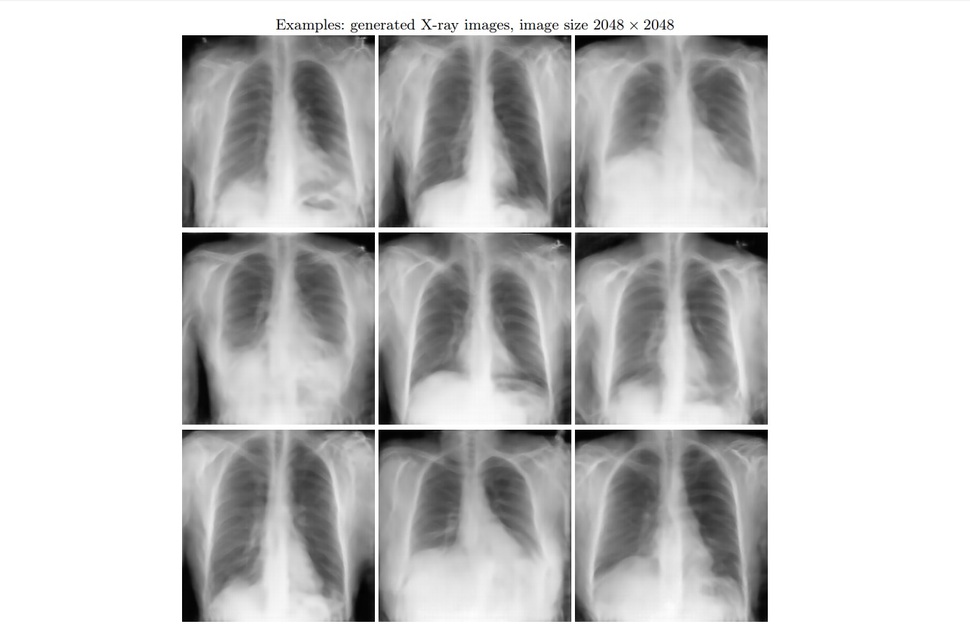
고해상도의 컴퓨터 단층(CT) 촬영과 자기공명영상(MRI) 사진을 ‘만들어 내는’ 데 성공했다.[링크] 아시다시피 얻기 어려운 빅데이터 가운데에도 내밀한 개인정보인 개인의 의료 데이터는 더 얻기 쉽지 않다. 이들이 만들어 낸 사진은 존재 하지 않는 인간의 데이터이지만, 워낙 사실적이어서 다른 인공지능이 학습용으로 쓰기에는 충분한 것이었다. 이를 활용하면 민감한 데이터가 필요한 인공지능의 경우 적은 데이터만으로도 많은 수의 ‘가상’ 데이터를 보태서 충분히 학습을 할 수 있다.
 |
|
적대적 생성 신경망(GANs)이라는 인공지능 기술을 이용해 만들어낸 가짜 의료 사진. 고해상의 사실적인 데이터이기 때문에 다른 인공지능의 학습에 사용할 수 있다. 아카이브 논문에서 갈무리. https://arxiv.org/abs/1907.01376
|
벤 딕슨은 언급하지 않았지만 여기에 빼 놓을 수 없는 것이 구글이 개발한
연합 학습(federated learning)[링크]이다. 이 기술은 서버로부터 원본 데이터를 가져오지 않고, 인공지능의 복사본을 서버로 보내서 공부하게 하고, 그 유학한 인공지능을 데려와 추가로 배운 부분을 활용하는 기술이다. 복잡한 인공지능의 학습 방법 상, 인간은 유학하고 온 인공지능만 보아선 원본 데이터가 무엇인지 알기 힘들다. 이 기술도 잘 활용하면 굳이 빅데이터를 축적할 필요 없이 우수한 인공지능을 길러내는 길을 열 수 있다.
권오성 기자 sage5th@hani.co.kr
광고

){kind=link}
){kind=link}
){kind=link}
){kind=link}
){kind=link}

기사공유하기